Abstract
Bimanual dexterous tool use remains challenging for robots due to high-dimensional hand configurations and complex hand-tool-object dynamics and contact. Most existing control policies depend on future configuration references provided from demonstrations, while future action-conditioned world models require slow online planning over high-dimensional action sequences. A significant challenge is generating a dynamically consistent future reference trajectory without relying on privileged states from demonstrations or slow counterfactual planning. We propose DexFuture, a hierarchical system that couples a high-level Future-State Visuomotor Target Predictor with a low-level Target-Conditioned Structured Dexterous Policy. Conditioned on egocentric RGB, proprioceptive and geometric history, the high-level predictor constructs structured hand-tool-object visuomotor embeddings and uses a horizon-conditioned transformer to generate a multi-step future target trajectory. Then, the low-level policy tracks them with a target-conditioned per-link transformer. This hierarchy decouples coarse future reference generation from fine-grained action control, and slow long-horizon semantic prediction from high-frequency execution. On OakInk2 bimanual tool-use tasks, DexFuture achieves 90% of the privileged-oracle performance, compared to 7% for a no-reference policy. DexFuture operates at 60 Hz, approximately 250 times faster than DexWM-style Cross-Entropy Method (CEM) planning with a future action-conditioned world model.
Contributions
Overview
DexFuture is a hierarchical system for bimanual dexterous tool use that couples a high-level Future-State Visuomotor Target Predictor with a low-level Target-Conditioned Structured Dexterous Policy. It removes the need for privileged future demonstration targets by predicting a coarse future-state target trajectory from visuomotor history. The predicted targets provide long-horizon guidance for the low-level policy to execute high-frequency contact-rich actions.
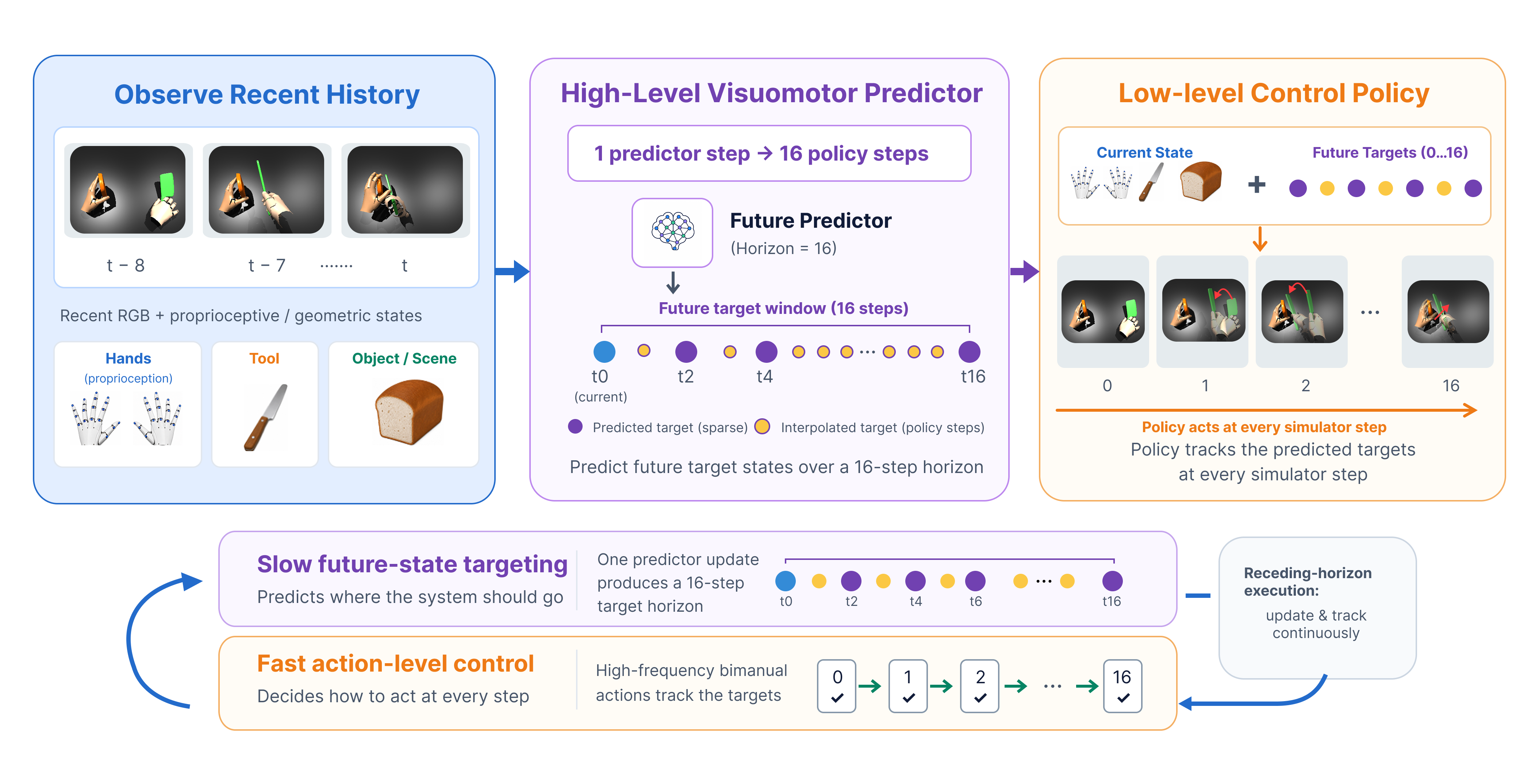
Method
A. Given recent egocentric RGB observations and proprioceptive/geometric states, we construct structured visuomotor tokens instead of passing dense image patches to the predictor. Hand-link embeddings are obtained by projecting each link into the image and cross-attending to local visual patches, while tool/object embeddings are built by anchor-aligned visual sampling and entity-state/geometry embeddings. B. The Horizon-Conditioned Target Transformer takes the structured embedding history as memory and predicts sparse future structured embeddings at horizons $\mathcal{H}=\{0,2,4,\ldots,16\}$. Future embeddings are first initialized from the latest observed state and modulated with learned future-index embeddings and Fourier horizon encodings, then refined via self-attention and cross-attention to the visuomotor history using AdaLN-Zero transformer blocks. The predicted embeddings are decoded into auxiliary geometric states for supervision, and a $900$-D future target used by the low-level policy. C. The target-conditioned structured dexterous policy consumes the current state and the predicted target, tokenizes the bimanual hand-tool-object system into per-link and scene embeddings, and outputs a bimanual action distribution through a transformer encoder and policy head. D. During receding-horizon execution, a single forward pass of the visuomotor predictor produces a target trajectory over multiple time steps. Intermediate targets are linearly interpolated to allow high-frequency feedback control. The predictor is trained with supervised latent, state, and target losses, while the policy is trained with PPO against a tracking reward.
Results
Bimanual Tool-Use Tasks
DexWM-Style CEM-based MPC planning
BibTeX
@misc{dexfuture,
title={DexFuture: Hierarchical Future-State Visuomotor Targeting for Bimanual Dexterous Tool Use},
author={Runfa Blark Li and Kuang-Ting Tu and Nikola Raicevic and Dwait Bhatt and Xinshuang Liu and Keito Suzuki and Ki Myung Brian Lee and Nikolay Atanasov and Truong Nguyen},
year={2026},
eprint={2606.05699},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2606.05699},
}